Convolution Neural Network
Convolutional Neural Networks (CNN) is one of the variants of neural networks used heavily in the field of Computer Vision. It derives its name from the type of hidden layers it consists of. The hidden layers of a CNN typically consist of convolutional layers, pooling layers, fully connected layers, and normalization layers. Here it simply means that instead of using the normal activation functions, convolution and pooling functions are used as activation functions.
CNN learns the filters automatically without mentioning it explicitly. These filters help in extracting the right and relevant features from the input data.CNN captures the spatial features from an image. Spatial features refer to the arrangement of pixels and the relationship between them in an image. They help us in identifying the object accurately, the location of an object, as well as its relation with other objects in an image.CNN also follows the concept of parameter sharing. A single filter is applied across different parts of an input to produce a feature map.
Convolutional Neural Networks have three important architectural features. Local Connectivity: Neurons in one layer are only connected to neurons in the next layer that are spatially close to them. This design trims the vast majority of connections between consecutive layers, but keeps the ones that carry the most useful information. The assumption made here is that the input data has spatial significance, or in the example of computer vision, the relationship between two distant pixels is probably less significant than two close neighbors. Shared Weights: This is the concept that makes CNNs "convolutional." By forcing the neurons of one layer to share weights, the forward pass (feeding data through the network) becomes the equivalent of convolving a filter over the image to produce a new image. The training of CNNs then becomes the task of learning filters (deciding what features you should look for in the data.) Pooling and ReLU: CNNs have two non-linearities: pooling layers and ReLU functions. Pooling layers consider a block of input data and simply pass on the maximum value. Doing this reduces the size of the output and requires no added parameters to learn, so pooling layers are often used to regulate the size of the network and keep the system below a computational limit. The ReLU function takes one input, x, and returns the maximum of {0, x}. ReLU(x) = argmax(x, 0). This introduces a similar effect to tanh(x) or sigmoid(x) as non-linearities to increase the model's expressive power.
Table
| CNN Models | Test Accuracy | Test Loss | F1-Score |
|---|---|---|---|
| 1-conv-32-nodes-0-dense | 86 | 1.77 | 86 |
| 2-conv-32-nodes-0-dense | 85 | 0.76 | 85 |
| 3-conv-32-nodes-0-dense | 90 | 0.48 | 90 |
| 1-conv-64-nodes-0-dense | 85 | 2.39 | 85 |
| 2-conv-64-nodes-0-dense | 89 | 0.55 | 89 |
| 3-conv-64-nodes-0-dense | 89 | 0.55 | 89 |
| 1-conv-128-nodes-0-dense | 84 | 1.36 | 84 |
| 2-conv-128-nodes-0-dense | 82 | 1.01 | 81 |
| 3-conv-128-nodes-0-dense | 86 | 0.95 | 86 |
| 1-conv-32-nodes-1-dense | 24 | 1.38 | 10 |
| 2-conv-32-nodes-1-dense | 88 | 0.59 | 89 |
| 3-conv-32-nodes-1-dense | 86 | 0.58 | 86 |
| 1-conv-64-nodes-1-dense | 26 | 1.36 | 13 |
| 2-conv-64-nodes-1-dense | 88 | 0.48 | 89 |
| 3-conv-64-nodes-1-dense | 88 | 0.54 | 89 |
| 1-conv-128-nodes-1-dense | 85 | 0.73 | 85 |
| 2-conv-128-nodes-1-dense | 85 | 0.77 | 83 |
| 3-conv-128-nodes-1-dense | 90 | 0.43 | 91 |
| 1-conv-32-nodes-2-dense | 24 | 1.38 | 10 |
| 2-conv-32-nodes-2-dense | 24 | 1.38 | 10 |
| 3-conv-32-nodes-2-dense | 63 | 0.84 | 57 |
| 1-conv-64-nodes-2-dense | 24 | 1.38 | 10 |
| 2-conv-64-nodes-2-dense | 83 | 0.70 | 83 |
| 3-conv-64-nodes-2-dense | 85 | 0.55 | 86 |
| 1-conv-128-nodes-2-dense | 24 | 0.00 | 10 |
| 2-conv-128-nodes-2-dense | 85 | 0.78 | 87 |
| 3-conv-128-nodes-2-dense | 85 | 0.64 | 85 |
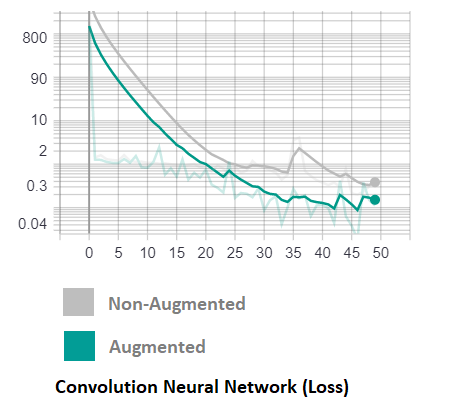
Convolution Neural Network
Among the Twenty-seven so models trained on the training data and validated on Testing data, we can see that a CNN model consisting of 3 Convolution layers and 1 Dense layer of 128 nodes yeilds higher accuracy and lower loss.
Thus we tweeked the model obtained and our best CNN model consists of 3 Convolution Layers of filter size of 64 and 2 Dense Layers each consisting of 128 nodes within the layer.The input layer was of size (150,150,3). This model was trained for 50 epochs, using the loss function 'sparse-categorical-crossentropy' and activation function 'ReLu' after each layer. However 'softmax' activation was used for output layer. The batch size of '64' and 'RMSprop' optimizer was used. However to prevent overfitting of data we introduce a slight drop-out of '10%' after few layers. The learning rate of '0.001' combined with few callbacks of Early-Stopping, Loss Monitering were called in the fit function.Thus the 'hdf5' file was generated. Below are the graphs for better understanding of how the training process for the model went.
 labelled.png)